Introduction
Tahano Hikamu (literally the ‘Round Script’), also simply known as tahano ‘script’, is the script usually employed to write Ayeri. This script is rather complex – so much, in fact, that it is currently still difficult to typeset it properly with computers. During its long development, letters changed shapes a little, but we will focus here on contemporary use and on the general rules that govern the script and use the ‘book’ style for the letters. There is also another variant with more stylized characters (hinyan ‘angular’), introduced in this blog article and exemplified in this supplementary brochure. A very in-depth description of the script is provided by chapter 2 of the Ayeri Grammar. You can also download a font of this, Tagāti Book G. How some things could be simplified for day-to-day handwriting is illustrated in this blog article.


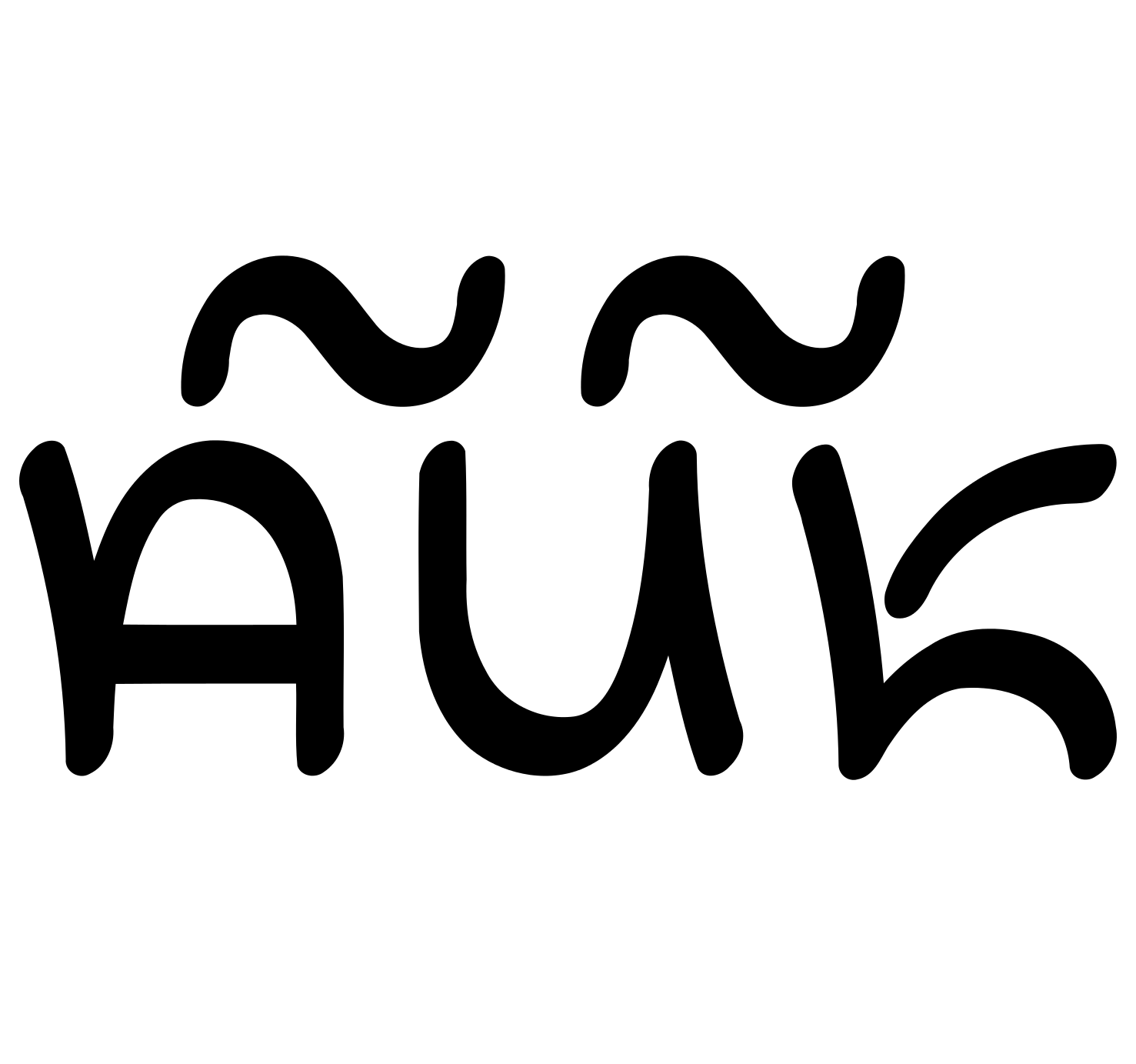
Consonants
This script works similarly to the ones found in India and elsewhere in Southern and Southeastern Asia – it is a syllabic alphabet, or abugida. This means that consonants serve as bases or matrices for the vowels, which in turn are written as diacritics. Different than in the scripts of the Semitic languages, writing out vowels is obligatory here, except for the vowel a, which is never written when it follows a consonant immediately, as it is inherent to every consonant letter. Letters do not have special names, but they are plainly called pa, ba, ta, da etc. This script is commonly written in horizontal lines from left to right, top to bottom, like the Latin alphabet.
The following chart gives an overview of all consonants that are needed to write Ayeri, with pronunciations in IPA:

- pa

- ta

- ka

- ba

- da

- ga

- ma

- na

- ŋa

- va

- sa

- ha

- ra

- la

- ja

- Ø (ʔa)
The place holder, or ranyan, is used when there is no consonant base that a vowel can be written on, which is, for example, the case for word-initial vowels. It has no sound value of its own in Ayeri. In languages with a phonemic glottal stop, it may also serve as a letter for that (sound value /ʔa/). Note that if another na follows a na, the first of them is slightly reduced and ligated with the second one:

nana ligature
To suit the needs of other languages that are also habitually written with this script, additional characters have been invented:

- fa

- wa

- za

- ʃa

- ʒa

- ça

- xa

- ɣa

- t͡sa

- k͡wa, k͡va

- k͡sa
The pronunciations given here are the most common ones, but individual languages may change things in order to adapt the script to their needs.
Vowels
It has already been mentioned above that vowels are written as diacritics. These can appear on top of or below a consonant and alter the pronunciation of the syllable. Every consonant has two vowel slots. The first one is above the consonant, the second one is below it. Since vowels are always understood to belong to the preceding consonant, the inherent /a/ is replaced by the vowel that is written above the consonant:

pa → pe
The top diacritics for the vowels are as follows:

- i

- e

- (a)

- o

- u

- au

- ə
Of course, as an /a/ is inherent to all consonant letters, the a top-diacritic itself basically only occurs with ranyan at the beginning of words. Note that Ayeri itself does not make use of ə. It is only listed here for completeness.
Top-diacritic o is also found written as  .
.
Two consecutive vowels do not occur much in English, but in Ayeri, for example, this may well be the case. For this purpose, another slot for a vowel is added below the consonant character, as mentioned above:

pa → pe → pea
The first slot of the consonant pa in the example above is already used for e, however, there is still an /a/ at the end of the syllable, which – if it was not indicated below the consonant – would be swallowed by the e. This works the same way with all other vowels as well.
Vowels are written like this when put under a consonant:

- i

- e

- a

- o

- u

- au

- ə
Note that very often, the consonants with ascenders, such as ka, da, ça will have the vowel written under them also in the case of a monovocalic syllable, since crossing the ascender with a vowel is considered unesthetic, although necessary on occasion. The empty top-slot is indicated by a dot here:

ka → ke → kea
Bottom-diacritic o is also found written  .
.
Diacritics
Tahano Hikamu has a plethora of additional diacritics which serve the purpose of marking the alteration of vowels or consonants. The following ones are written under consonants:
| Grapheme | Definition |
|---|---|
 | tupasati: long vowel |
 | ringaya: palatalization of consonant |
 | ya eyra: consonant + /ja/ |
 | ulangaya: aspiration of consonant |
 | vināti: homorganic nasal or nasalization |
 | kusangisāti: geminated consonant |
 | gondaya: no inherent /a/ |
 | raypāya eyra: vowel + /ʔ/ or glottalization |
Some of these – namely tupasati (‘long maker’), ya eyra (‘low ya’), ringaya (‘raiser’), and ulangaya (‘breather’) – can also precede the consonant under certain circumstances: This is the case
- with consonants without a right downstroke or bowl to attach to:

naː, ŋaː, vaː, waː - with consonants following na:

napaː - when there would be two bottom-attaching diacritics:

ta → ti → tiː → t͡ʃiː (*tjiː) → t͡ʃiːe (*tjiːe)
As can be seen in the example to (3) above, diacritic reordering can produce very complex results, as vowels and “small” diacritics like gondaya and vināti can still be put underneath “large” diacritics such as tupasati, ya eyra, etc. — in the t͡ʃiː step of (3), tupasati is drawn before the consonant ta so as to be able to attach the ya eyra under the consonant. Also note that na typically has gondaya, vināti and kusangisāti written over it rather than under it.
These are the diacritics that attach in front of consonants:
| Grapheme | Definition |
|---|---|
 | tupasati marin: long vowel |
 | lentankusang: diphthong with /ɪ/ |
 | tilamaya: systematically changed vowel (i.e. umlaut) |
 | ringaya marin: palatalization of consonant |
| ya marin: consonant + /ja/ |
 | hiyamaya: retroflex consonant |
 | ulangaya marin: aspiration of consonant |
Note that it is correct here that ringaya/ya marin has the same shape. Also note that lentankusang, tilamaya and hiyamaya can only occur in this position, and that when stacking diacritics to the front of consonants, the stacking goes from right to left, beginning with those diacritics modifying the consonant, then those modifying the vowel, with the lentankusang diacritic following (from right to left) tupasati marin:

na → nja → njaː → njaːɪ
Also note that rule (2) above is overridden if na is followed by a consonant which has a diacritic attached to its front:

napjaː
Last but not least, there are diacritics that attach to the top of consonants. The bottom versions of these are preferred if there is a counterpart, however, the reordering to the top is convenient sometimes, e.g. in the special case of na having no space underneath it to attach diacritics.
| Grapheme | Definition |
|---|---|
 | gondaya ling: no inherent /a/ |
 | kusangisāti ling: geminated consonant |
 | vināti ling: homorganic nasal or nasalization |
 | raypāya: vowel + /ʔ/ or glottalization |
Note that it is also possible for gondaya to appear after a consonant at the end of a word: 
Numbers
Ayeri uses a duodecimal number-place system, so there are separate figures for 10 (A) and 11 (B) as well as from 0 to 9.

- 0

- 1

- 2

- 3

- 4

- 5

- 6

- 7

- 8

- 9

- A

- B
Punctuation
These are the commonly used punctuation marks:
| Grapheme | Definition |
|---|---|
 | dan: full stop |
 | damprantan: question |
 or or  | dambahān: exclamation |
 | puntān: dash |
 | danarān: quotation |
 | dandan: abbreviation and marking clitics, reduplication etc. |
 | dansinday: decimal point |
Punctuation in Ayeri is very elaborate as the tables above show. Note that instead of a comma, a wide word space is used. Clauses themselves are usually written as one string, or with only little space between individual words. The puntān, or dash, serves the function of both dashes and colons. The two forms of the dambahān, or exclamation mark, are interchangeable, however, the horizontal version is preferred at the end of paragraphs, and also for very strong exclamations. The dandan is used to indicate abbreviated words or syllables, but it is also used to mark clitics:


bttn. (= batitasan, ‘abbreviation’); ada-savayam ‘to that wagon’
The full stop sign (‘dan’) is occasionally also found written as  , i.e. two small circles above each other.
, i.e. two small circles above each other.
These punctuation marks are less commonly used:
| Grapheme | Definition |
|---|---|
 | adrumaya: line break |
 | dankayvo: brackets |
 … …  | dangaran: name |
Adrumaya indicates a line break within a clause explicitly. The pair of dankayvo works like our parentheses. Morever, the script does not have capitalization, however, it may be desirable sometimes to mark names as such explicitly, which is when the pair of dangaran is used – basically like a special kind of parenthesis.
Abbreviations
| Grapheme | Definition |
|---|---|
 | nay ‘and’ |
 | naynay ‘also, too, furthermore’ |
An Example
This is a translation of the first article of the United Nation’s Universal Declaration of Human Rights into Ayeri and rendered in the Tahano Hikamu script:

The above reads in normal romanization:
Sa vesayon keynam-ikan tiganeri nay kaytanyeri sino
nay kamo. Ri toraytos tenuban nay iprang, nay ang
mya rankyon sitanyās ku-netu.
Note that there is usually little to no space between the individual words of a sentence. Syntactic breaks where one would put a comma in Latin transcription are indicated with a wide space. Due to the size of diacritics and the ability to stack them, the line height is usually much larger than in Latin typesetting.